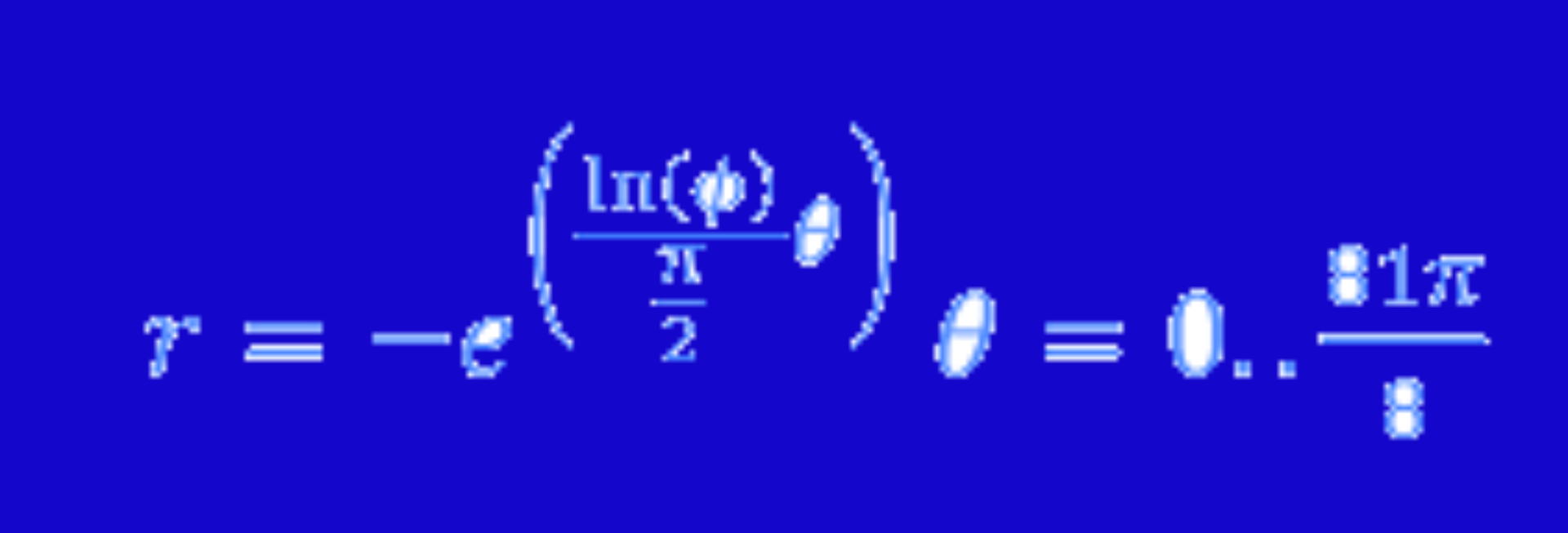Because I love genetic algorithms and video games, I always wanted to create some artificial intelligence that learns to play a game. My first attempt is the subject of this entry.
A college friend and roommate of mine once showed me how he used a GA to solve the two bishops chess endgame scenario from any position. I decided that it would be fun, and within my capabilities to focus on a simpler game, Mancala.
What’s a Genetic Algorithm?
A GA is just a search. If a search space is simply too large to enumerate in a reasonable amount of time, a GA provides a means of finding a “good enough” solution without searching through every possible one. In practice, this usually means waiting quite some time (maybe a few days) for the algorithm to run, but the reward is usually a damn good solution.  A GA attempts to model biological evolution by simplifying it to three stages. After starting with a potential pool of solutions, we assign each of them a fitness value, select the ones with the “best” fitness (selection), use them to create “offspring” solutions (crossover), optionally mutate the offspring (mutation), and start again with the newly created pool of solutions. Let’s see how this applies to the Mancala game.
A GA attempts to model biological evolution by simplifying it to three stages. After starting with a potential pool of solutions, we assign each of them a fitness value, select the ones with the “best” fitness (selection), use them to create “offspring” solutions (crossover), optionally mutate the offspring (mutation), and start again with the newly created pool of solutions. Let’s see how this applies to the Mancala game.
What’s a Mancala?
Mancala is a very simple two-player, turn-based board game where each player has a row of buckets with some stones in them and a scoring bin. Each player takes a turn by emptying one of the buckets and placing one stone in each consecutive bucket (including the scoring bin) until no stones remain. There are a few other rules, but the object is to finish with the most stones in your scoring bin.
In a somewhat unfortunate circumstance, I found out after implementing my algorithm that Mancala is a solve game, meaning that someone has figured out the perfect move for every position, and given that both players know the perfect move, the outcome is predetermined. The most familiar example of a solved game is probably tic-tac-toe. It’s easy to guarantee a draw, even if you don’t get the first move. Now, forgetting that we ever saw this, let’s go searching.
How to Teach a Computer to Play:
We need just a few things to build an algorithm – a way to value the current game board (this is the AI part, which I will henceforth call a “strategy”), a way to select the best strategies, a way to create new strategies from old ones, and a way to mutate strategies. These methods will define a GA which helps us efficiently search the space of all possible strategies.
Choosing a Valuation Strategy
I chose to value the current state of the board based upon three properties – the net score (



That player would calculate the following values for the parameters described:
The player’s score is 





")
")
")




I’ve chosen to restrict the weights to the range ![[0,1]](https://web.archive.org/web/20160415024214im_/http://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=000&s=0 "[0,1]")


If we just so happened to choose values 
*.1 + (-9)*.1 + 3*.9 = 1.7")
I should quickly note why this valuation is important. Since, Mancala is a two-player, turn-based game, we can employ a minimax algorithm when deciding to make a move. This roughly means that on each turn we look at the move that maximizes the board value for us, while leaving the opponent the least room to improve their board value. The deeper we search in the move list, the better we can limit our opponents moves. I chose to search seven moves deep mostly because I didn’t want to run the algorithm for any more than two days, : ).
The minimax algorithm could be the topic of its own post, but I’ll save that for a later date because we need to get on to the business of selecting strategies for crossover.
Assigning Fitness
I chose to have every strategy in the pool play against every other strategy twice, alternating who goes first, and define “fitness” for each strategy as the number of wins it achieved that round. Once fitness is determined for each strategy in the pool (i.e. every match has been decided), I chose two parent strategies at random, but proportional to their fitness, for the crossover phase, which creates the next pool of strategies.
For a simple example, suppose the pool size were 


")
 Strategy 1 gets the range
Strategy 1 gets the range ")
")
")
")
We need four parents, so we sample this distribution four times. Note that we could get the first strategy each time we sample, but we could also get strategy 3 for all four parents, illustrating why a pool size of four is generally a bad idea. Since playing the actual matches is the most time-consuming part of the process, the choice of pool size actually represents a trade-off between the time we’re willing to spend letting the algorithm run and the variety of strategies we’d like to search. I chose a pool size of forty.
Making Babies – Digitally
I’ll describe the algorithm for creating child strategies from parents shortly, but first, I’m going to name the strategies for ease of reference. I’ll call parent 1 Wes, parent 2 Mara, and the two child strategies will be named Miles and Sophie, who come about in the following way:
Miles gets the average of the weights of Wes and Mara. Sophie gets 


Wes:

Mara:

Then Miles looks like this:

Miles:

And Sophie gets:
Sophie: 





This may seem a somewhat odd choice. I would agree, but since I’m not using a binary coding for the system, I didn’t think a simple one-point crossover (where Miles would have simply gotten the values not assigned to Sophie) would provide enough variety. So, I chose this hybrid crossover/average method for creating children instead.
Mutation
Each child then gets a chance for a slight variation in each of the three parameters. In my case, I chose to shift each parameter up or down by a random amount sampled from a normal distribution centered at zero with a standard deviation of 
After mutation, we now have a fresh pool of strategies to start all over again, but when will it end? I simply chose to run the algorithm for a static number of generations (75), keeping track of the most fit strategy (the one with the highest number of wins) over the course of the entire run. Each run took about three days, so I only did three of them.
What Did My Computer Learn?

The best strategies I found over the course of three runs were as follows:
1:
")
2:
")
3:
")
There are some similarities among all three, and very obviously among the last two. For instance, score is always weighted highest, just a little higher than balance of stones, and roughly twice as high as the overflow parameter. Since I could have appealed to intuition to tell me that score is the most important factor, these results make me reasonably confident that the algorithm found a good solution. While I had no prediction for the relative weights of the balance and overflow parameters, the results are at least not shocking. Controlling more stones is really quite important, though not quite so important as scoring, and overflow, while certainly bad, can’t be expected to match the value of the other two parameters, and it clearly doesn’t. In fact, based on the results, I might try an even simpler board valuation technique that only considers score and balance.
The real test, however, is how competitive the strategy is against a real human. The best strategy gave me a real challenge. It was several matches before I found a weakness, and several more before I was able to beat it, but even then I abused my knowledge of how it played to do so. The really fun part about using a GA is that I never told any of the strategies the object of the game. I merely asked them to value the state of the game in different ways, and then pitted them against each other to see whose valuations were best.
I’ve made the code available, so if you’re inclined, you can try it yourself. The project was built with VS 2008 as a C++ project. It’s fairly shoddy code, but it works and it’s fun! Enjoy.